
Estimated reading time: 4 minutes
The digital bank has built a simplified backup platform with six engineers and costing just 1% of its total cloud bill, allowing customers to access their money during an outage.
In today’s world, where nearly every financial interaction – from buying groceries to paying rent – depends on digital infrastructure, reliability isn’t a luxury; it’s a necessity.
For a bank like Monzo, with over 12 million customers and no branches to fall back on, even a brief outage can have outsized consequences: failed card payments, frozen balances, and customers stranded without access to their money.
How do you build a banking platform that can keep working – even when your primary systems go completely dark?
At LeadDev’s LDX3 2025, Monzo’s senior staff engineer Andrew Lawson and distinguished engineer Daniel Chatfield explained how they built an entirely separate fallback platform from scratch – not to prevent failure, but to withstand it.
“When thinking about how we make Monzo the most reliable bank that we can, we want to think not just about the failures of servers and data centers, but also acknowledging that we’re all human writing software, and that software will constrain bugs,” said Chatfield.
Even big banks go down
Despite the vast resources and infrastructure investment poured into resilience by UK retail banks, service outages remain common.
Between January 2023 and February 2025, nine major UK banks and building societies experienced a total of at least 803 hours of unplanned IT outages, equivalent to over 33 days. These disruptions affected millions of customers and resulted in 158 separate incidents.
The banks involved include Barclays, HSBC, Lloyds, Nationwide, Santander, NatWest, Danske Bank, Bank of Ireland, and Allied Irish Bank.
Monzo itself has faced high-profile outages, including as recently as June 2025, which left many customers unable to access their accounts or make payments.
Your inbox, upgraded.
Receive weekly engineering insights to level up your leadership approach.
The Stand-in Platform
To address the limitations of traditional disaster recovery in the face of software failure, Monzo built a secondary banking system – known internally as the Stand-in platform – which was launched in March 2025.
As Chatfield put it, the goal was to “build a system that can still provide our customers with a good service even if our software has bugs.”
Unlike conventional backups, Stand-in is not a replica of Monzo’s main platform. It’s a standalone, minimal, independent system designed to keep customers running during outages by using different data and infrastructure for added resilience.
Hosted entirely on Google Cloud – separate from Monzo’s primary AWS setup – Stand-in prioritizes independence over perfect isolation to reduce the risk posed by shared software bugs or platform issues.
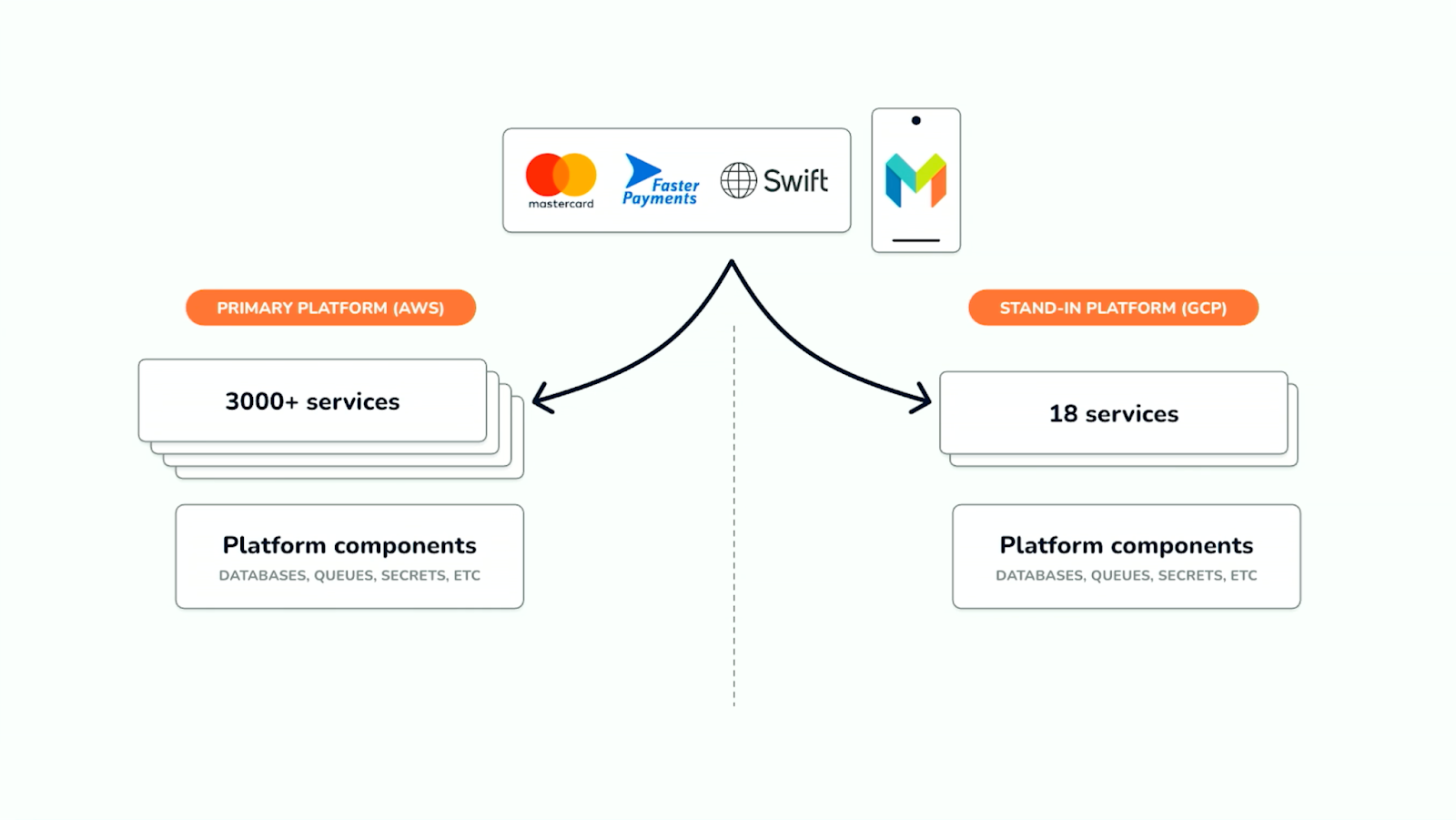
While the main platform runs 30,000+ microservices, Stand-in uses just 18 purpose-built services focused on critical day-to-day banking functionality such as making card payments, withdrawing cash, sending bank transfers, viewing balances, and freezing a card. Customers see a simplified, pared-back interface as a result.
This reduction in scope increases resilience and gives customers access to what they need most – like paying for transport and groceries, or securing their account – even if the main system is down.
The Monzo Stand-in backup banking system was first tested with users during an August 2024 outage that temporarily impacted Monzo’s payment processing and app functionality.
More like this
No replacement for the basics
That being said, building a reliable platform has to start with the fundamentals. “It’s got to start with getting the basics of platform resiliency right,” Chatfield said.
Traditionally, this meant making individual servers more robust using techniques like redundant arrays of independent storage disks or error-correcting memory.
Modern cloud infrastructure is designed to tolerate failure by default. Monzo, like many large-scale technology companies, draws on the model pioneered by Google – distributing systems across clusters of servers and multiple data centres.
“We’ve solved for the failure of an individual server,” said Chatfield. “We’ve [solved the] failure of an entire availability zone or data center.”
Despite redundancy in hardware and infrastructure, the biggest source of failure now lies in the software itself. “There is another class of failure, which is software failure,” Chatfield explained. “If the bug is in the software, then just running it more times doesn’t really help you.”
And unlike hardware failures, which are random and often recoverable, software bugs are deterministic. “If it has a bug, it’s still going to have a bug the second time you run it,” Chatfield said.
This kind of software failure is significantly more likely than hardware faults and often harder to mitigate. “The risk of outage is typically dominated by bugs in the software itself, and it doesn’t do a great job of dealing with those sorts of failures,” said Chatfield.
Even more advanced strategies, like fully active multi-cloud architectures, fall short. “Every database operation, every message emitted on a queue needs to be coordinated across at least three clouds,” Lawson said.

Berlin • November 9 & 10, 2026
Engineering leadership has never moved this fast.
See how other leaders are keeping pace at LeadDev Berlin.
That coordination introduces latency and complexity that degrade the user experience – particularly for a bank like Monzo that processes “multiple millions of data operations a second.”
And even if the infrastructure is spread across clouds, the same code still runs on all of them. “If it is the same software deployed to each,” Lawson said, “then the software failure will obviously take all of them down.”
By accepting that failures will happen, a team of six engineers has been able to establish a firm fallback option for customers, costing just 1% of its total cloud platform spend.
For a more detailed look at how Monzo developed the Stand-in platform, you can watch the whole talk from LDX3 here.




