Jamstack, the modern way to write production applications, has redefined the way we look at frontend development today.
The frontend experience now is decoupled from the backend (or there is no backend at all due to the rise of serverless architectures), served as static assets via the content delivery network (CDN), and communicates with backend services through API endpoints.
Pure frontend experiences are becoming increasingly more powerful and complicated, needing increased investment and attention to how they are built and deployed to the customers. The times where the entire frontend could be backed into a Java monolith, could fit into 2 JavaScript files and 50KB (half of which was jQuery), and controlled a few dropdowns, are long gone. Now, we can write and deploy complete interactive user experiences without writing a single ‘backend’ line of code.
Because of that, having a separate CI/CD (Continuous Integration and Continuous Delivery) pipeline for frontend is something that has become more and more popular, and eventually, it will likely be the default in the industry.
The insights in the article come from working for four years on a product with more than 300 active developers and millions of users, that embraced the Jamstack concept and continuous delivery principles. It has its new frontend written with a modern tech stack and an independent CI/CD pipeline.
You are not in control
Probably the biggest difference between the frontend and backend world, which sometimes goes underestimated or unnoticed, is the lack of control. After JavaScript is packed and uploaded to the CDN, it’s not yours anymore. It’s controlled by users and the conditions under which they interact with it – whether that’s a slow network connection, a peculiar choice of browsers, or a 10-year old laptop with 2GB of memory. If something starts to go wrong, you can’t simply throw money at the problem and scale up your instance to buy some time to figure out why.

Since the code is not yours anymore, the only data that you can get when the code leaves the staging environment is completely dependent on: whether users interact with the part of the experience you want to monitor; whether it is instrumented explicitly; and whether the experience can send events back to the monitoring service – usually via a normal REST endpoint. The code is like Schrödinger’s cat in a soundproof box – you can’t guess if it’s alive by listening for its meowing or scratching, you’ll only know whether it’s dead or alive when someone opens that box.
With that in mind, the ‘CI’ part of the CI/CD pipeline is more crucial than ever, since it’s the last time you’ll have full control over the code. There are a number of automations and safety checks that can be implemented here – I like to separate them into the following logical groups:
- Code health. Making sure that your code, as a set of independent modules, works and is healthy. This would typically include all sorts of linting tools, typing checks, security checks, and unit tests.
- Experience health. Making sure that your experience as a whole works by running various integration and end-to-end tests.
- Experience looks. Visual regression tests go here! This is frontend we’re talking about after all, and what the customers see when they interact with the product is as important as what the customers can do.
So in the ideal world, the CI pipeline would look something like this:

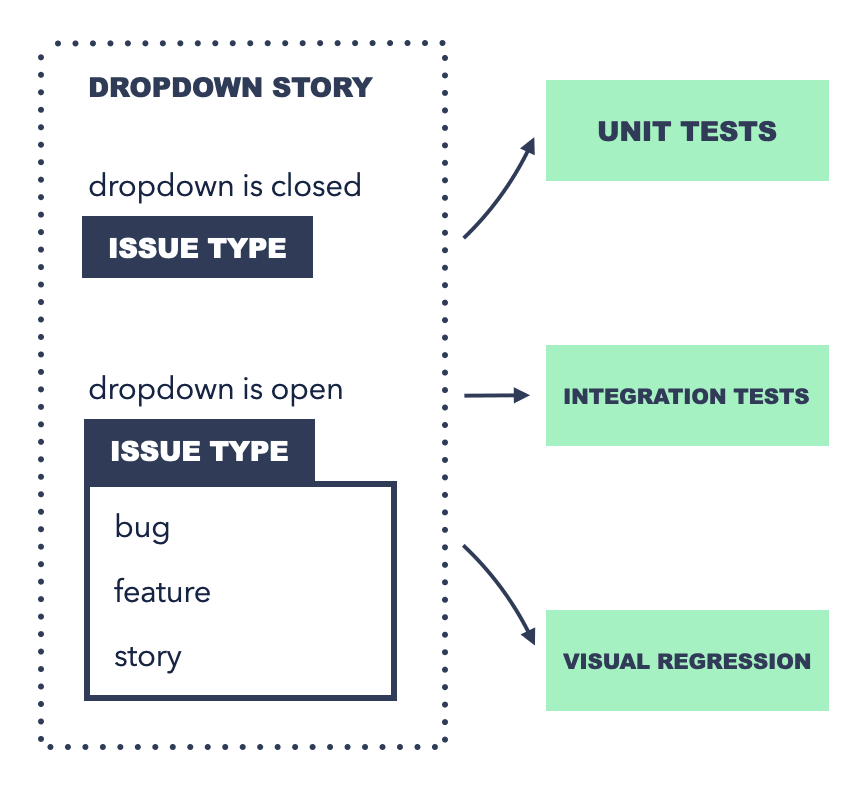
One of the little tricks to make this setup easier to write and maintain, that we developed in this product, was to write code in a way that means the same set of tools can be used for all three areas. For example, a dropdown component that shows a list of issue types would be:
- Written in isolation as a component ‘story’ with an open and closed state, and with strong typing and unit tests that check render output in both states;
- The same story would be used by robots to click on the dropdown and verify that it still works;
- The same story would be used to take a screenshot and compare it with the base story in the main branch to verify that it still looks the same.
All or nothing
Another tricky part in frontend development is its radical nature: more often than not there is no such thing as a slowly degrading experience or high load problems that only affect large customers. If something is broken, it’s broken for all at the same time.
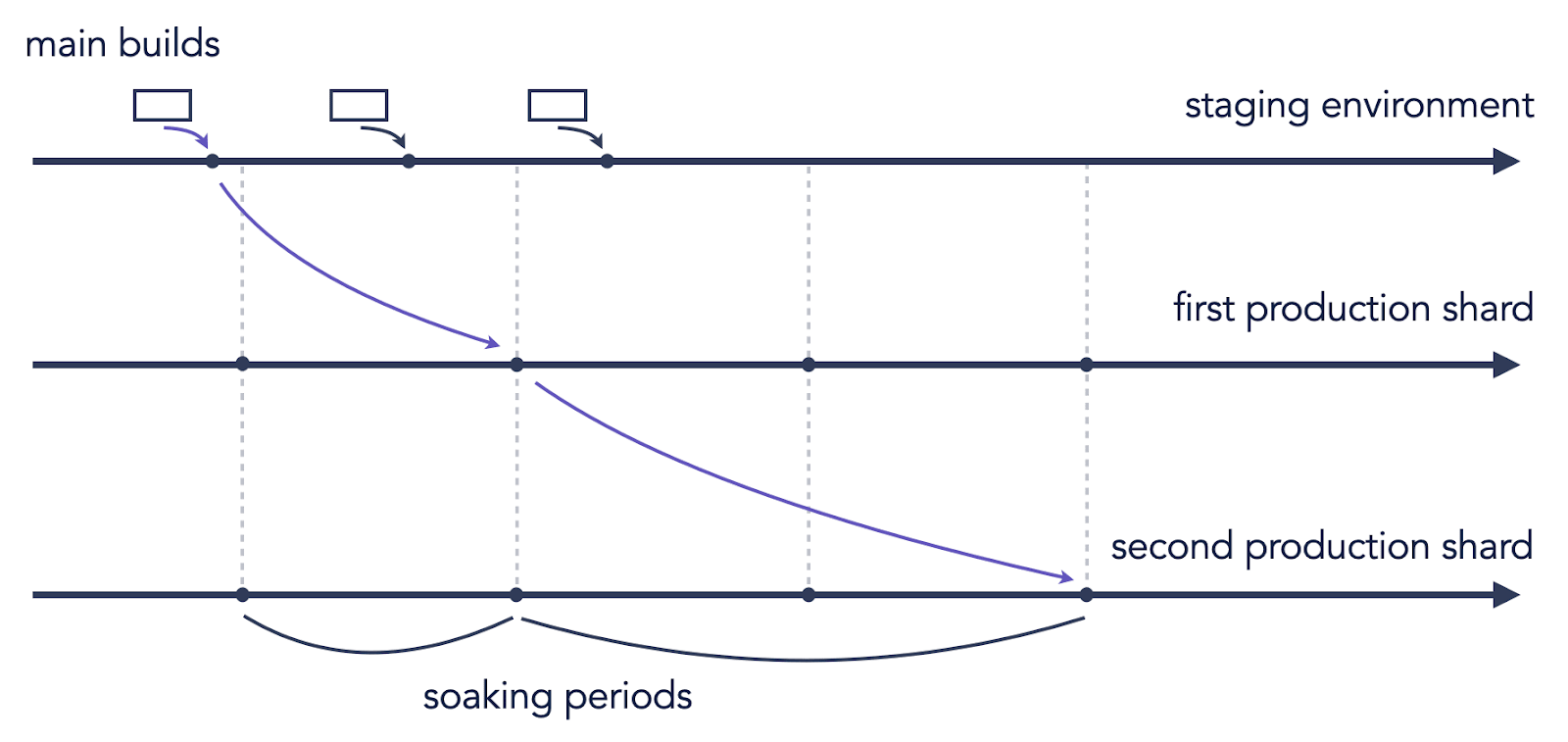
One way to mitigate this problem is to introduce a concept of ‘staged deployments’ – when you isolate users into groups and deploy to every group independently, step by step. This reduces the blast radius of an incident if it happens and allows engineers to detect a degraded experience early on and before it reaches 100% of customers.
Imagine it looking something like this: when code is built in the main branch and all tests have passed, it is deployed to internal instances and staging environments. It sits there for a certain period of time (‘the soaking period’), giving the opportunity to detect troubles before they reach the actual customers. After the code is ‘mature’ enough, it is propagated to the next environment with a very small subset of users, then to the next one, and again, until it reaches 100% of customers.
Another concept that is quite useful when you need to either hide a feature temporarily in active development, slowly release it to a percentage of users, or just roll out a risky change, is ‘feature flags’. From the code perspective, it looks like a simple ‘if (isFeatureEnabled()) { do this } else { do that }’ statement, where the information of whether a feature is enabled or not comes from backend or an external service. The most important thing here is the ability to change the value instantly without the need to rebuild or redeploy anything.
The dark side of continuous delivery
One of the key concepts of continuous delivery is to release changes often and in small chunks, which greatly increases reliability of the system and teams’ development speed. When it comes to frontend though, there is a caveat in this approach: caching.
In the end, the entire frontend experience is nothing more than just a bunch of JavaScript files that browsers need to download before they can execute them. When it comes to CI/CD, this means that every time JavaScript is changed and a new version is deployed, browsers need to download it first. This may not only be costly for the users (there are still places where people pay for the download!), but it also can slow down the initial load of the application and negatively impact performance numbers. Basically, every frontend release comes at the price of slightly degrading user experience temporarily.
There is no silver bullet solution here, and the strategies to mitigate the impact highly depend on the bundler that is used to build JavaScript, knowing the users and the state of their internet connection, and the processes that are implemented in the organization. Be mindful of this when implementing CI/CD pipeline for frontend experiences and your users will be grateful for blazing-fast UI and a small 3G connection bill.




